

DeepSeek-V3 Comparison, Benchmarks, Limitations, and Deployment Analysis
Model Architectures & Scale: DeepSeek‑V3 is a Mixture-of-Experts (MoE) Transformer with 671 billion total parameters (only ~37B “active” per token). It uses Multi‑Head Latent Attention and a novel multi-token prediction objective for efficiency. In contrast, GPT‑4 is proprietary (rumored ~1.76 trillion parameters) with context windows up to 32K tokens, and Claude 3.5 Sonnet is closed-source (~175B parameters by reports) with a 200K-token context window. Meta’s LLaMA-3 series are dense models (up to 405B parameters) with 128K context. Unlike these dense models, DeepSeek‑V3’s MoE design means only a small subset of parameters are used per inference step, greatly reducing compute and memory needs. Notably, DeepSeek‑V3 was trained on 14.8 trillion tokens using an FP8 mixed-precision framework, achieving stable training in ~2.788 million H800 GPU-hours (∼$5.6M), far less than comparable dense models. All DeepSeek code is open-source (MIT license) and the model weights are available on GitHub/HuggingFace, supporting commercial use.
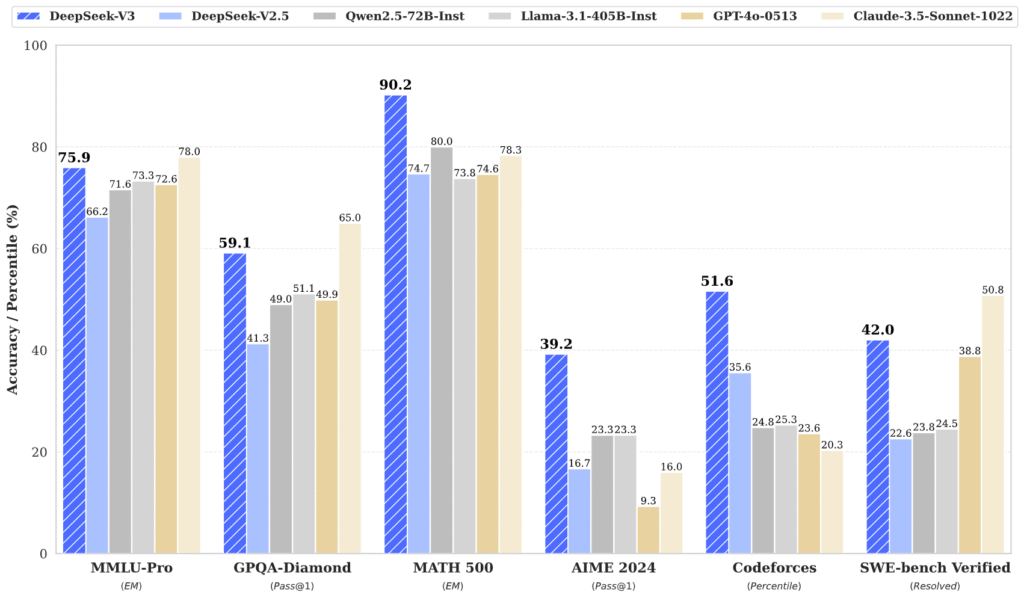
Performance Benchmarks: DeepSeek‑V3 delivers state-of-the-art results on many tasks, often matching or exceeding GPT-4 and Claude. For example, on the English MMLU benchmark, DS3 scores ~88.5% (vs. 87.2% for GPT‑4o); on DROP reading comprehension (F1), DS3 reaches 91.6 vs. 83.7 for GPT‑4o. In coding tasks (HumanEval multilingual), DS3 achieves 82.6% pass@1, slightly above GPT‑4o’s 80.5% and Claude Sonnet’s 81.7%. On math reasoning (MATH-500), DS3 (90.2%) far outpaces both GPT‑4o (~74%) and Claude (78.3%). In Chinese benchmarks, DS3 is especially strong: for instance, on the Chinese C-Eval exam DS3 scores 86.5% vs. 76.0% for GPT‑4o. A summary of key comparisons:
English MMLU (Multi-Task Language Understanding): 88.5% (DeepSeek‑V3) vs. 87.2% (GPT‑4o).
DROP (Reading Comprehension): F1=91.6 (DS3) vs. 83.7 (GPT‑4o).
HumanEval (Multilingual Code, pass@1): 82.6% (DS3) vs. 80.5% (GPT‑4o).
MATH‑500 (Mathematical Reasoning): 90.2% (DS3) vs. ~74–78% (GPT‑4o/Claude).
Chinese C-Eval: 86.5% (DS3) vs. 76.0% (GPT‑4o).
These figures reflect extensive internal evaluations. Indeed, a recent report notes DeepSeek‑V3 “outperformed the other models on a majority of tests, including five coding benchmarks and three mathematics benchmarks”. In practice, DS3 matches LLaMA-3’s 405B performance despite using far fewer active parameters. (GPT‑4 and Claude excel on some specific subtasks, e.g. SimpleQA and vision-related tests, but overall DS3 is competitive.)
Evaluation Results
Base Model
Standard Benchmarks
| Benchmark (Metric) | # Shots | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 | |
|---|---|---|---|---|---|---|
| Architecture | – | MoE | Dense | Dense | MoE | |
| # Activated Params | – | 21B | 72B | 405B | 37B | |
| # Total Params | – | 236B | 72B | 405B | 671B | |
| English | Pile-test (BPB) | – | 0.606 | 0.638 | 0.542 | 0.548 |
| BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | 87.5 | |
| MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | 87.1 | |
| MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | 86.2 | |
| MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | 64.4 | |
| DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | 89.0 | |
| ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | 98.9 | |
| ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | 95.3 | 95.3 | |
| HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | 89.2 | 88.9 | |
| PIQA (Acc.) | 0-shot | 83.9 | 82.6 | 85.9 | 84.7 | |
| WinoGrande (Acc.) | 5-shot | 86.3 | 82.3 | 85.2 | 84.9 | |
| RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | 74.2 | 67.1 | |
| RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | 56.8 | 51.3 | |
| TriviaQA (EM) | 5-shot | 80.0 | 71.9 | 82.7 | 82.9 | |
| NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | 41.5 | 40.0 | |
| AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | 79.6 | |
| Code | HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | 65.2 |
| MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | 75.4 | |
| LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | 19.4 | |
| CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | 67.3 | |
| CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | 69.8 | |
| Math | GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | 89.3 |
| MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | 61.6 | |
| MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | 79.8 | |
| CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | 90.7 | |
| Chinese | CLUEWSC (EM) | 5-shot | 82.0 | 82.5 | 83.0 | 82.7 |
| C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | 90.1 | |
| CMMLU (Acc.) | 5-shot | 84.0 | 89.5 | 73.7 | 88.8 | |
| CMRC (EM) | 1-shot | 77.4 | 75.8 | 76.0 | 76.3 | |
| C3 (Acc.) | 0-shot | 77.4 | 76.7 | 79.7 | 78.6 | |
| CCPM (Acc.) | 0-shot | 93.0 | 88.5 | 78.6 | 92.0 | |
| Multilingual | MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | 79.4 |
Note: Best results are shown in bold. Scores with a gap not exceeding 0.3 are considered to be at the same level. DeepSeek-V3 achieves the best performance on most benchmarks, especially on math and code tasks. For more evaluation details, please check our paper.
Independent Evaluations & Use Cases: Several third-party analyses highlight DS3’s capabilities. InfoQ reports that DeepSeek‑V3, trained with ~2.788M GPU-hours, “outperforms other open-source models on a range of LLM benchmarks, including MMLU”. It also notes DS3 beat GPT‑4o and Claude‑Sonnet on most coding and math tests. Blog posts and forums emphasize DS3’s cost-efficiency: as Simon Willison observes, DS3’s ~$5.6M training cost (2.788M H800 hours) was only ~1/11th that of LLaMA‑3.1 405B, yet DS3 “benchmarks slightly better” on many tasks.
DeepSeek‑V3 is already integrated into commercial platforms. It is listed in Google Cloud’s Vertex AI Model Garden, where serving DS3 requires 2 instances of 8× NVIDIA H100 GPUs (16 H100 total). Enterprises can access it via DeepSeek’s own chat interface (chat.deepseek.com) or an OpenAI-compatible API. New Relic has added DS3 to its AI monitoring suite, alongside OpenAI and Claude, enabling real-time performance/cost tracking. Use-case write-ups demonstrate DS3 driving real-world applications: for example, it can power multilingual customer-support chatbots and personalized tutoring systems with high fidelity. (The DeepSeek team even provides a demo code and supports commercial use.)
Criticisms & Limitations: Despite its strengths, DeepSeek‑V3 has caveats. The model is extremely large and resource-hungry: practical deployments have required massive multi-GPU setups. Even the authors concede “limitations, especially on the deployment”, noting that while DS3 is ~2× faster than its predecessor, further speedups depend on more advanced hardware. Like all LLMs, DS3 can hallucinate or produce inconsistent answers. Anecdotally, one report found DS3 “mistakenly identif[ying] itself as ChatGPT” when trained on web data containing ChatGPT outputs, highlighting risks of data contamination. Concerns have been raised about biased content: testers observed that DS3 refused to answer politically sensitive questions about China while answering analogous questions about other countries, suggesting possible censorship-aligned behavior. Moreover, as a Chinese-developed model, DS3 raises privacy and security flags: it sends all user data (chat messages, personal info, etc.) to servers in China, which has reportedly led to bans on its use by the U.S. government for security reasons. In summary, DS3’s open access comes with the typical LLM caveats (bias/hallucination) and some unique geopolitical/privacy issues.
Expert & Community Insights: The AI community has been both impressed and alert. News outlets and blogs emphasize DeepSeek’s breakthrough: InfoQ notes DS3’s efficient training and that it “outperforms other open-source models and achieves performance comparable to leading closed-source models”. GitHub contributors and researchers pointed out DS3’s novel choices (FP8 precision, MLA, auxiliary-loss-free balancing) as key innovations. On social media, prominent technologists have chimed in: Simon Willison highlighted its training-efficiency and ranking among open models; independent evaluator Aldo Cortesi reported DS3 “tied for first with Sonnet” on coding tests while being twice as fast and making “ZERO prompt adherence errors”. On forums like Hacker News and Reddit, users have lauded DS3’s results and low inference cost (one user noted it was ~53× cheaper to run per token than Claude Sonnet for similar benchmarks). At the same time, some community members have warned about its “censored” nature or data issues. Overall, experts view DeepSeek‑V3 as a major open competitor – the highest-ranked openly licensed model to date – while also emphasizing the need for critical evaluation of its outputs and use.
Deployment & Inference Tooling
Deploying DeepSeek‑V3 requires specialized frameworks due to its MoE architecture and 8-bit precision. The DeepSeek team and community have enabled broad support:
SGLang (v0.4.1): A high-performance inference engine that fully supports MLA optimization, DP Attention, and FP8 for DS3. SGLang runs on both NVIDIA and AMD GPUs (day-one support) and can scale across machines with tensor parallelism.
LMDeploy: Microsoft’s inference/serving stack now supports DS3, offering flexible pipelines for FP8/BF16 inference.
TensorRT-LLM: NVIDIA’s library supports DS3 in BF16 and INT4/8 quantization modes; FP8 support is under development.
vLLM (v0.6.6): An open-source serving library that handles DS3 in FP8/BF16 on NVIDIA and AMD hardware, with pipeline parallelism for multi-node setups.
LightLLM (v1.0.1): Tencent’s LLM runtime supports single- or multi-machine deployment of DS3 (FP8/BF16), with ongoing work on deep quantization and memory disaggregation.
AMD GPUs: Thanks to collaboration with AMD, SGLang enables DS3 to run on Radeon Instinct (MI300) GPUs in both FP8 and BF16 modes.
Huawei Ascend NPUs: The MindIE framework from Huawei Ascend community now supports DS3’s BF16 model on their NPUs.
DeepSeek‑Infer Demo: A lightweight reference demo (in PyTorch) illustrates FP8/BF16 inference for DS3.
Together, these tools mean DS3 is “production-ready” on modern hardware. For example, Google Cloud’s Vertex AI uses a multi-host Triton/vLLM setup to achieve low latency. However, running DS3 still requires massive resources (the Vertex deployment uses 16× H100 GPUs). All frameworks help mitigate this: by using FP8 weights (with conversion to BF16 available) and optimized kernels, they cut memory and speed up inference. In summary, DeepSeek‑V3 benefits from a maturing ecosystem (SGLang, LMDeploy, TRT-LLM, vLLM, LightLLM, etc.) that makes large-scale deployment feasible, albeit still expensive and complex.
Sources: Recent technical reports, official model docs, and industry analyses were used throughout: the DeepSeek‑V3 arXiv paper and GitHub docs; benchmark tables from its Hugging Face model card; third-party articles (InfoQ, Google Cloud docs, New Relic blog); and community commentary (e.g. user benchmarks and observations). These provide a comprehensive, up-to-date comparison of DeepSeek‑V3 against GPT‑4, Claude, and LLaMA‑3 models.